随着 SSD 技术的不断进步,尤其是市场向 NVMe™ PCIe® 5.0 SSD 的转变,单个 SSD 现在可以实现高达 14GB/s 的顺序读取速度和 7GB/s 的顺序写入速度,同时还能处理数百万次输入/输出操作(IOps)。在现代服务器中,通常会配置 24 个或更多这样的高性能 SSD。由于单一应用程序可能无法完全利用这些高性能,多个虚拟机通常会在同一系统上运行。因此,确保在驱动器故障时的数据保护以及低延迟下的稳定性能变得尤为重要,特别是在处理关键任务应用程序时。
云服务(公共云和私有云)依赖于软件定义的方法,使它们能够在需要时按需部署资源。在本研究中,我们将探讨两种创建软件 RAID 阵列的方法,并将其作为虚拟机的存储资源使用。
测试目标
本次测试的目的是评估高性能 NVMe 驱动器的软件 RAID 阵列的适用性,并将创建的卷用于需要快速存储的虚拟机。我们计划展示该解决方案的可扩展性,并对测试结果进行评估。我们将考虑两种创建软件 RAID 阵列的方法:
-
mdraid :针对 NVMe SSD 的最佳性能配置,在 Linux 内核空间中运行;
-
Xinnor 的商业产品 xiRAID Opus :在用户空间中运行。
创建的卷通过 vhost 接口导出到虚拟机。vhost 目标是运行在主机上的一个进程,能够将虚拟化的块设备暴露给 QEMU 实例或其他任意进程。
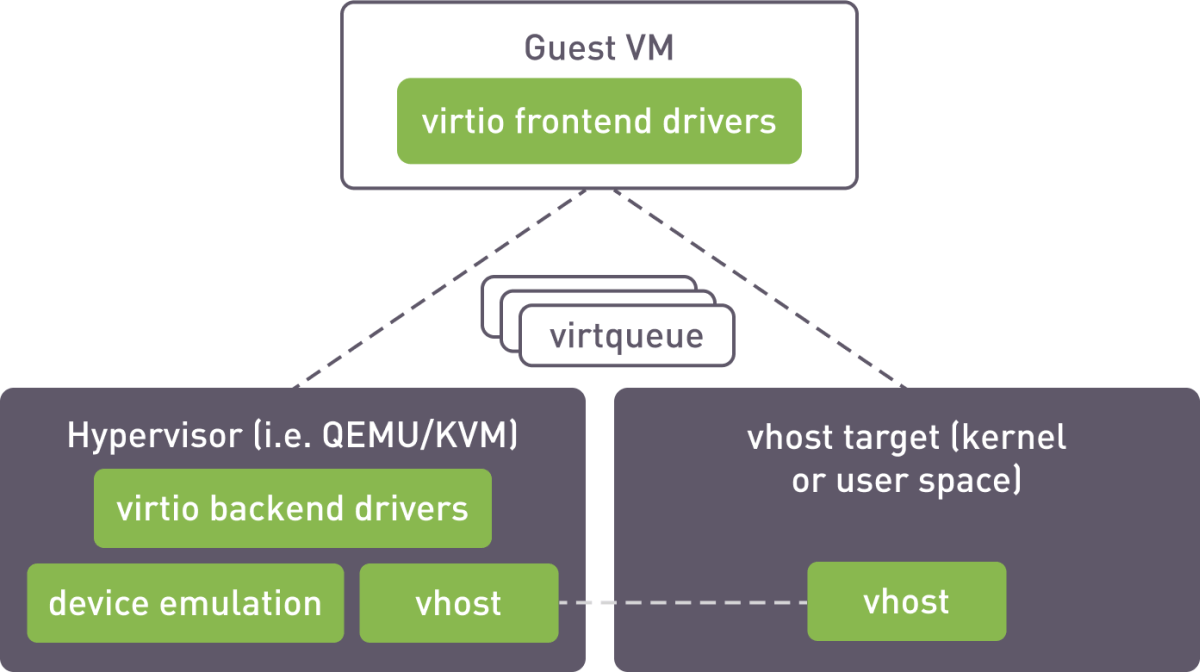
对于 mdraid,我们使用了内核 vhost 目标并通过 targrtcli 工具进行配置。xiRAID SPDK 有一个内置的目标,运行在用户空间中。
测试环境
硬件配置:
-
主板 :Supermicro H13DSH
-
CPU :双 AMD EPYC 9534 64 核处理器
-
内存 :773,672 MB
-
硬盘 :10 块 3.20 TB KIOXIA CM7 系列企业级 NVMe SSD(KCMYXVUG3T20)
软件配置:
-
操作系统 :Ubuntu 22.04.3 LTS
-
内核版本 :5.15.0-91-generic
-
xiRAID Opus 版本 :xnr-859
-
QEMU 模拟器版本 :6.2.0
RAID 配置
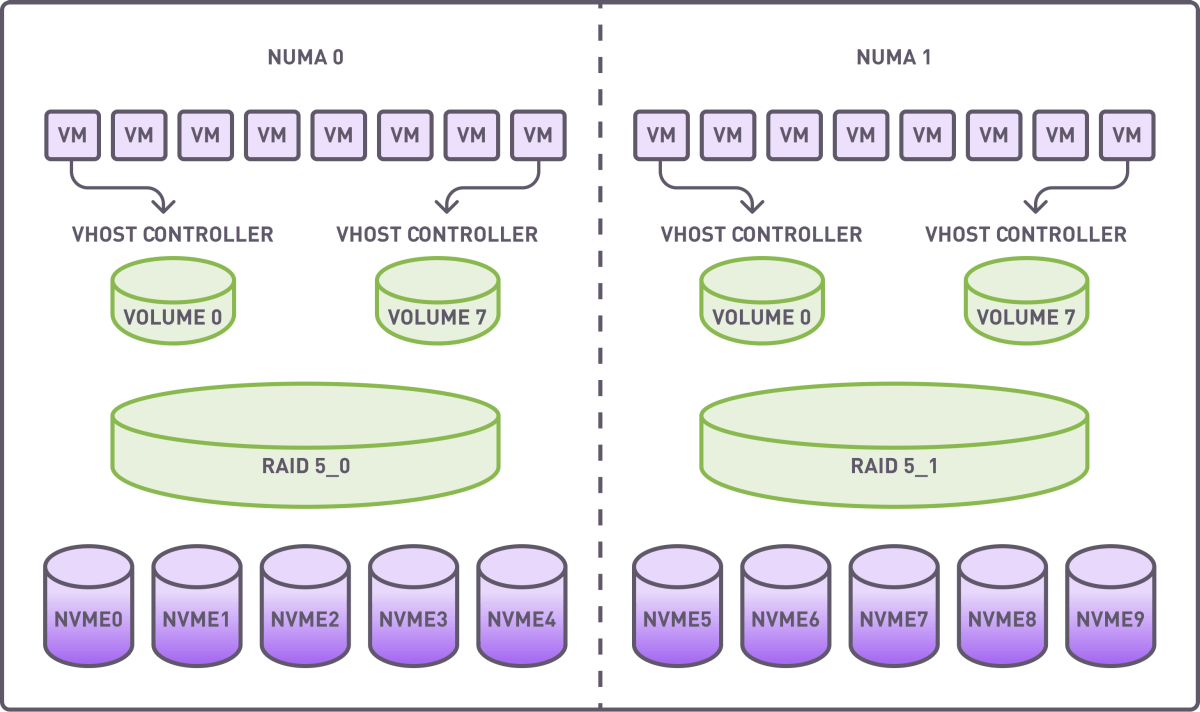
为了避免 NUMA 内部通信,我们创建了两个 RAID 组(4+1 配置),每个组使用来自单个 NUMA 的驱动器。条带大小设置为 64K。在基准测试之前进行了完整的 RAID 初始化。
每个 RAID 组被划分为 8 个段,每个段通过专用的 vhost 控制器分配给虚拟机。
资源分配总结:
-
RAID 组:2
-
卷:16
-
vhost 控制器:16
-
虚拟机:16,每个虚拟机使用分段的 RAID 卷作为存储设备.
CPU 具有 8 个核心复合芯片 (CCD),每个 CCD 包含 8 个 ZEN 核心,共享 L3 缓存。
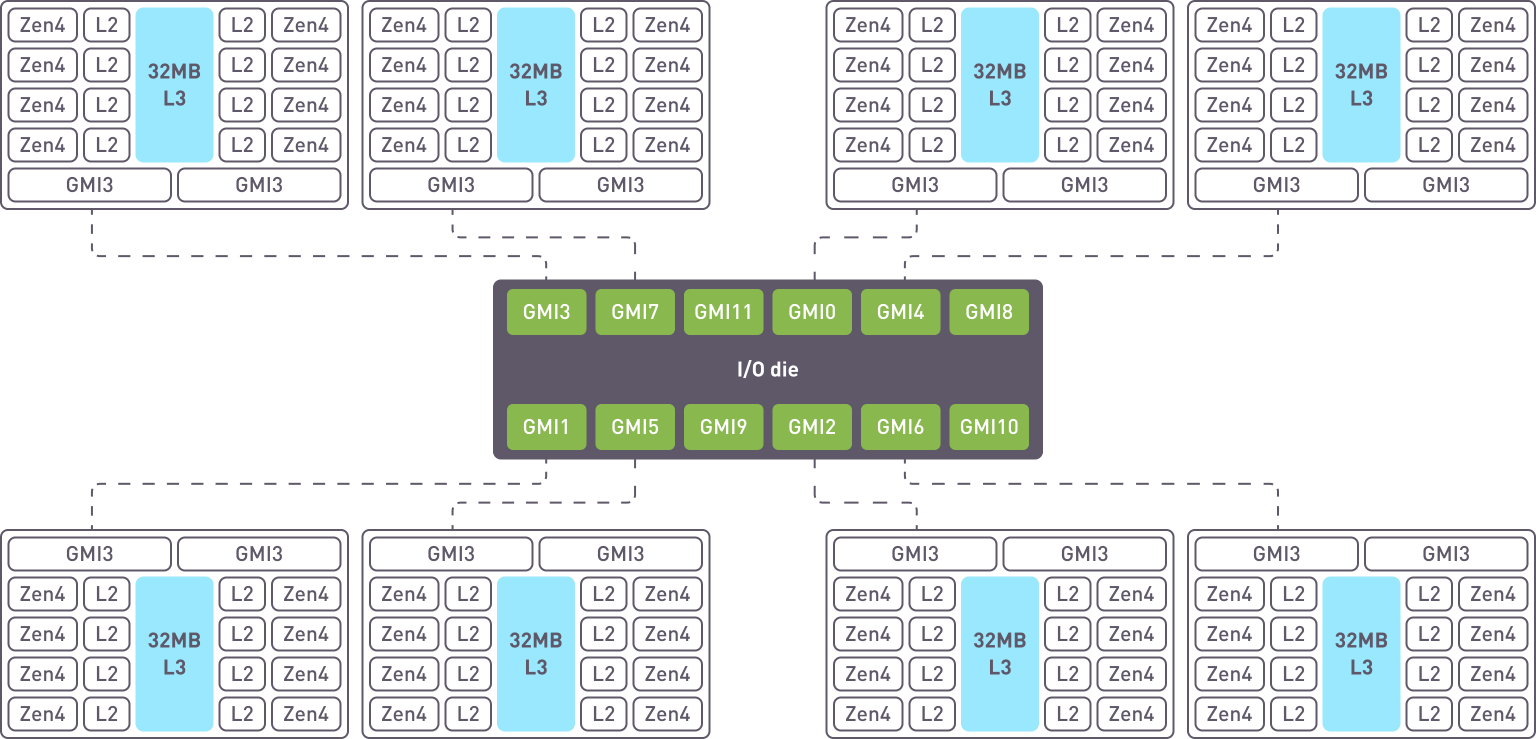
跨核心正确分配资源是实现高性能的关键组成部分。xiRAID Opus 的一个特点是允许用户指定哪些核心将专用于运行应用程序。
将虚拟机及其对应的 vhost 控制器放置在同一 CCD 上可以通过减少延迟和提高数据吞吐量来增强性能。这是因为利用了同一 CCD 内直接且更快的通信路径,而不是跨不同 CCD 的较慢路径。这种方法特别适用于需要高速数据处理和最低延迟的虚拟机系统。
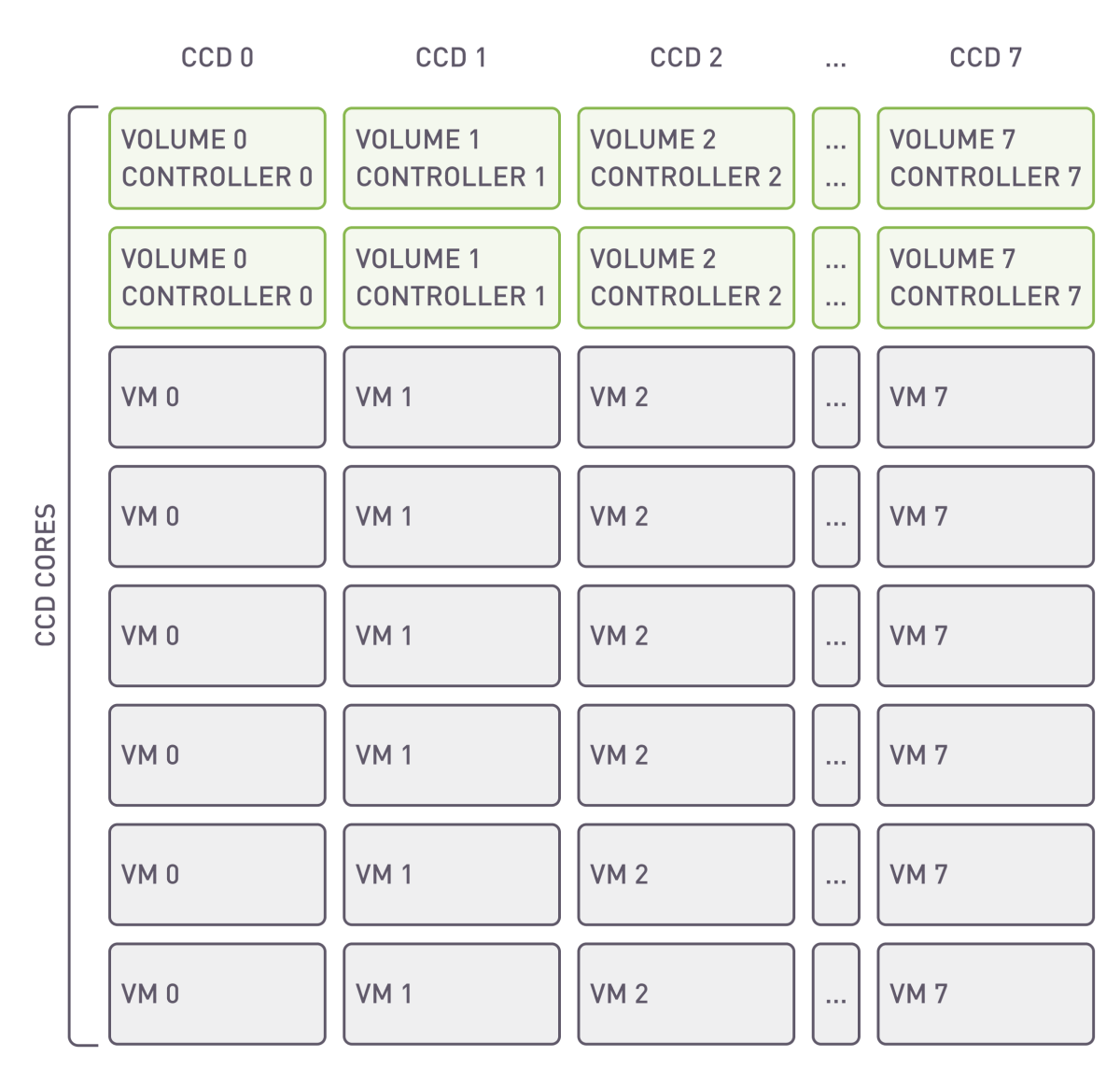
虚拟机配置
在使用 xiRAID Opus 和 mdraid 时,虚拟机的配置有所不同。在使用 xiRAID Opus 时,可以分配特定的核心,而剩余的核心则由虚拟机使用。而在内核空间中使用 mdraid 时,无法分配特定核心,所有核心会被同时用于存储基础设施和虚拟机。
CPU 分配:
每个虚拟机分配 6/8 个 vCPU,直接对应于主机服务器的物理 CPU 核心。通过 taskset 工具管理进程到核心的亲和性以优化性能。
QEMU CPU 配置:
QEMU 内存配置:
每个虚拟机通过 Hugepages 预分配 16 GB 内存。内存绑定到与分配的 vCPU 相同的 NUMA 节点,以确保高效的 CPU-内存交互。
操作系统:
虚拟机运行 Debian GNU/Linux 12 (Bookworm)。
基准测试工具:
使用 fio 工具,版本 3.33。
设置 xiRAID Opus 用于虚拟机基础设施
在本节中,我们将简要概述创建阵列、卷并将它们导出到虚拟机所需的步骤。有关详细说明,请参阅手册。
启动命令:
在 NumaNode 上运行具有 300GB HugePage 的应用程序,并在每个 CCD 上使用 2 个核心。
RAID 创建步骤:
-
驱动器连接 :使用
xnr_cli drive-manager连接驱动器。 -
RAID 创建 :使用以下命令创建 RAID 阵列:
-
初始化 :等待 RAID 初始化过程完成。
-
卷创建 :使用脚本为每个 RAID 创建 8 个卷:
-s 表示每个卷的大小
-
卷导出 :通过 vhost 控制器导出卷(每个控制器均需实现):
-c 是用于启动特定目标的掩码
测试配置概述
本次测试场景的目标是评估虚拟机(VM)使用 Vhost 目标时的累积性能,并评估 I/O 操作在多个 CPU 核心上的可扩展性。评估包括对单个虚拟机和一组 16 个虚拟机进行测试。每个虚拟机执行一系列 FIO 基准测试,以测量各种工作负载条件下的 I/O 性能,包括:
-
小型随机读取操作(4KiB)
-
小型随机写入操作(4KiB)
-
混合随机 I/O,读写比为 70:30(4KiB)
-
大型顺序读取操作(1MiB)
-
大型顺序写入操作(1MiB)
这些工作负载模拟了一系列场景,以全面了解系统的性能特征。
测试结果
小型随机操作测试结果
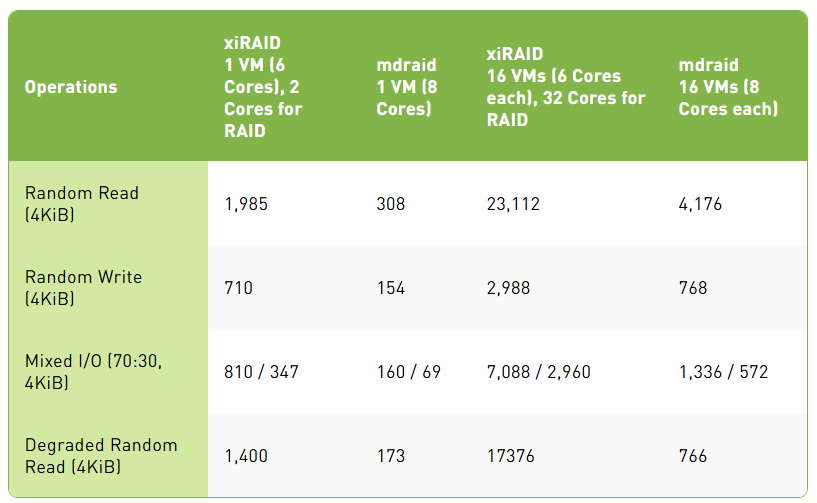
随机操作性能,K IOps
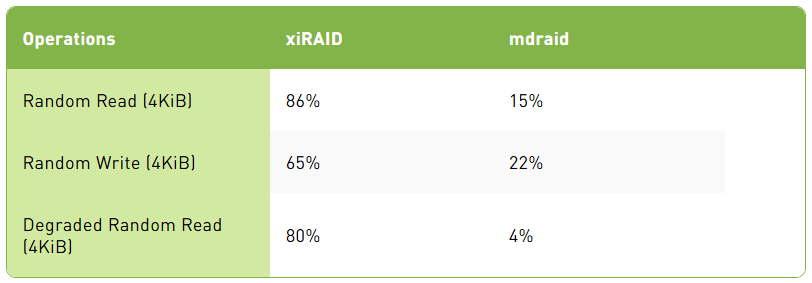
随机操作效率(16 个虚拟机)效率通过将 RAID 性能与 10 个驱动器的理论性能进行比较计算得出。每个驱动器的随机读取能力为 2.7 M IOps,随机写入能力为 0.7 M IOps。
平均延迟,µs
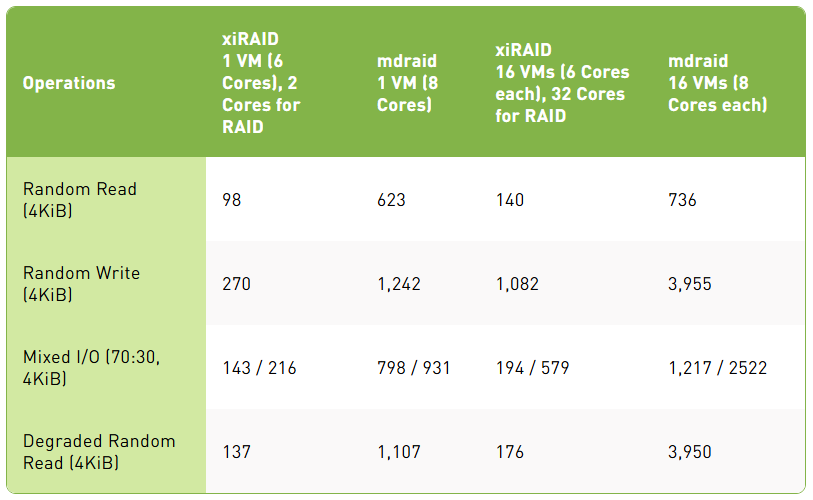
99.95 百分位延迟,µs
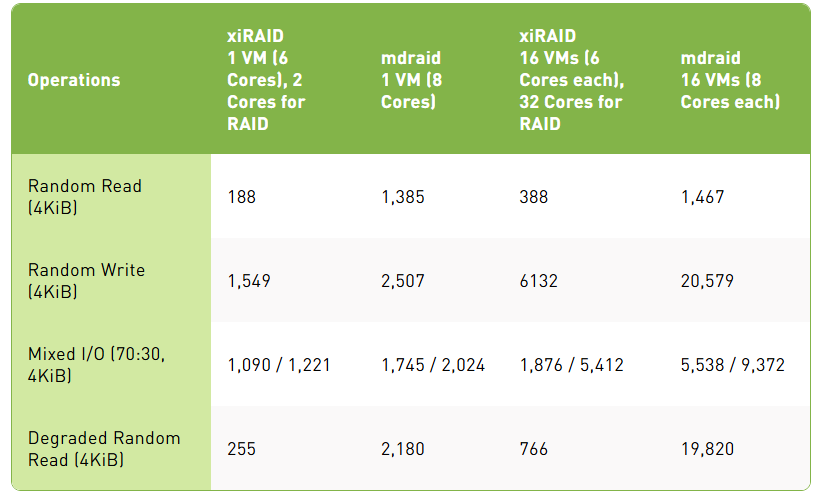
结果
随机读取在观察到的结果中,每个 RAID 配置都能够每核心提供接近一百万 IOps 的性能,同时保持显著的低延迟。结果非常出色,特别是对于延迟敏感的应用程序:单虚拟机 RAID 设置实现了低于 100 微秒的延迟水平,99.95 百分位延迟保持在 200 微秒以下。这些数字表明了卓越的性能,展示了系统在最小延迟下处理密集工作负载的能力。
在扩展时,由于 fio 工具消耗了所有可用的 CPU 资源,性能下降了约 30%。这表明扩展与 CPU 可用性之间存在权衡,在高负载条件下后者成为限制因素。
随机写入尽管 RAID 实现中的写入性能受到必要的额外读取-修改-写入操作的影响,但结果显示 xiRAID 比 MDRAID 高效 4 倍。
正如预期,在写入时,随着额外的读取-修改-写入周期增加资源争用,扩展损失更加明显。这种影响在扩展配置中尤为明显,其中许多虚拟机正在争夺相同的 CPU 资源。
降级模式 xiRAID 在降级模式下的读取性能比 MDRAID 高出 20 倍,显示了极小的性能损失和仅略微增加的延迟。这种在降级模式下的稳健性对于即使在部分系统故障或维护场景下仍需一致读取性能的应用程序尤其有利。
Mdraid 和内核空间目标显示出显著较低的效率水平,使其经济上不太可行。
顺序操作测试结果
顺序操作性能,K IOps
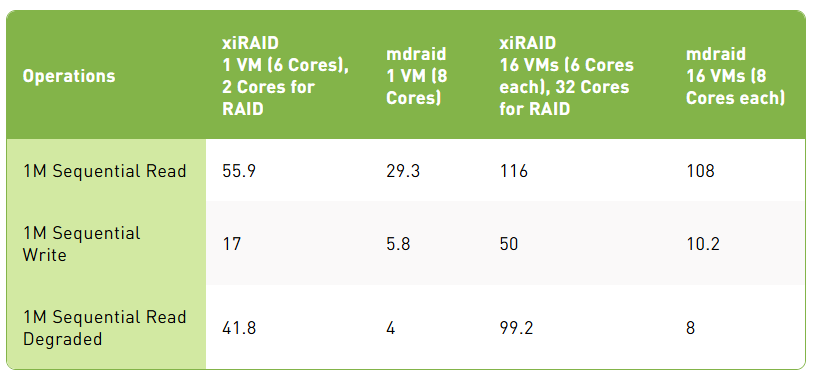
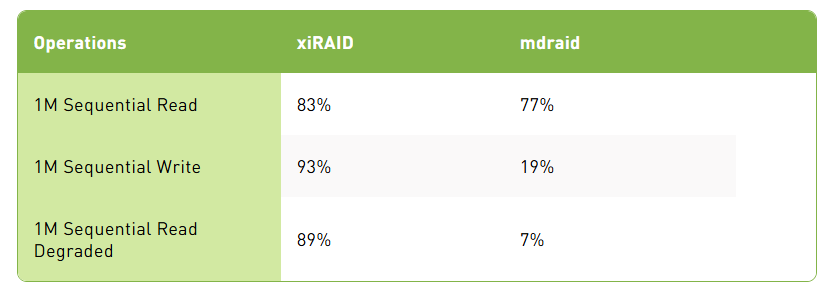
顺序操作效率(16 个虚拟机)效率通过与 10 个驱动器的理论性能进行比较计算得出,单个驱动器的性能如下:顺序读取 14 GB/s,顺序写入 6.75 GB/s。
结果
顺序操作的性能接近理论最大值,即使在降级模式下仍然保持高水平。这种稳健性允许在虚拟基础设施中部署数据密集型应用程序,确保它们即使在次优条件下也能高效运行而不会显著降低性能。
Mdraid 在降级模式下的顺序读取和顺序写入性能显著落后于 xiRAID,即使在小规模安装中也是如此,这使得该解决方案不适合对性能敏感的应用程序。
xiRAID Opus 概述
xiRAID Opus(用户空间优化性能)是 xiRAID 软件 RAID 引擎的用户空间版本。它利用 SPDK(存储性能开发工具包)库移出 Linux 内核,使客户无需担心 Linux 内核版本更新过程。此架构提供完全的 CPU 控制,便于与特定 CPU 核心的亲和性执行。xiRAID Opus 超越了 Linux 主机的限制,展示了适应性,便于移植到其他操作系统并与专用硬件(如数据处理单元 (DPU))无缝集成。xiRAID Opus 具有用于从虚拟基础设施访问数据的内置接口:vhost SPDK、NVMe-oF™。
总结
测试旨在评估使用 xiRAID Opus Vhost 的虚拟机(VM)的性能和可扩展性,重点是跨多个 CPU 核心的 I/O 操作。通过各种 FIO 基准测试,包括小型随机读取和写入、混合 I/O 和大型顺序操作,评估提供了系统在不同工作负载条件下的性能洞察。值得注意的是,结果显示每个 RAID 配置都可以每核心提供接近一百万 IOps 的性能,并且延迟极低。单虚拟机 RAID 设置表现出低于 100 微秒的卓越延迟水平,即使在高负载或降级模式下也表现出优越的性能。此外,顺序操作接近理论最大值,即使在驱动器故障的情况下也能确保高性能,从而支持在虚拟基础设施中高效部署数据密集型应用程序。
在性能方面,mdraid 和内核 vhost 目标显著落后于 xiRAID Opus。此外,某些设置的不一致性大大增加了管理任务的复杂性。Mdraid 在降级模式下表现出极低的效率,而这正是 RAID 存在的意义所在。
感谢阅读!如果您有任何问题或想法,请在评论区留言。JK软件官网团队很乐意听到您的反馈!